
1. Replication
DB 리플리케이션은 데이터베이스에서 데이터의 복제본을 생성하여 여러 위치에 저장하는 과정을 의미한다. 많은 DBMS에서 이러한 리플리케이션을 지원하며, 일반적으로 서버 사이에 master-slave 관계를 설정하고 데이터 원본은 master에, 사본은 slave에 저장하는 방식이다.

이때, 쓰기 연산은 마스터 서버에서만 지원하고, 슬레이브 서버는 읽기 연산만을 지원하게 된다. 쓰기 연산이란 데이터의 상태를 변경하는 Insert, Update, Delete를 칭하며 이들은 마스터 서버에게만 전달된다.
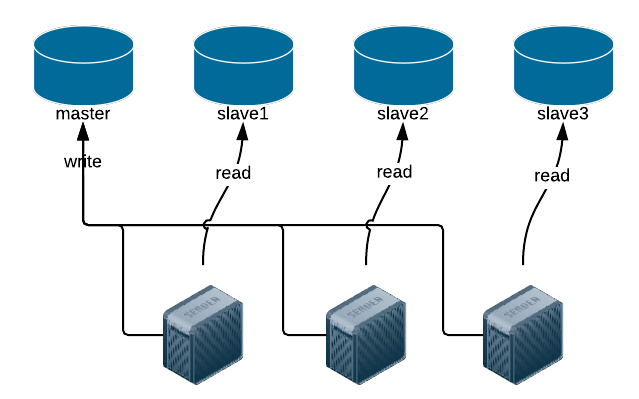
대부분의 애플리케이션은 쓰기 연산보다 읽기 연산의 비중이 훨씬 높으므로 일반적으로 슬레이브의 수를 더 많이 두게 된다.
장점
리플리케이션의 장점은 다음과 같이 정리할 수 있다.
1. 더 나은 성능
master-slave의 구조에서 읽기 연산은 슬레이브 서버로 분산되기 때문에 병렬로 처리될 수 있는 쿼리 수가 늘어나므로 성능이 좋아진다.
2. 안전성
자연 재해 등의 이유로 일부 데이터베이스 서버가 손실되어도 다른 지역에 위치한 데이터베이스를 이용하면 된다.
3. 가용성
마찬가지로 데이터의 사본이 여러 슬레이브 서버에 저장되있기 때문에, 한 데이터베이스 서버에 장애가 발생하더라도 다른 데이터베이스에서 데이터를 가져오면 된다.
2. 리플리케이션 전략
마스터 서버에서 데이터 변경을 처리하게 되면 해당 변경사항을 로그 파일에 기록하게 된다. 이후 슬레이브 서버에서 마스터의 로그를 읽고, 기록된 변경 사항을 자신의 데이터베이스에 적용하게 된다.
이때 리플리케이션의 전략은 동기와 비동기로 나뉘게 되는데..
2.1. 동기 리플리케이션

동기 리플리케이션은 마스터 서버에서 변경 사항이 발생했을 때, 해당 변경 사항이 모든 슬레이브 서버에 적용되는 것을 확인한 후에야 트랜잭션이 완료되는 방식이다. 데이터 일관성이 높지만 지연 시간(latency)이 길어져 성능 저하가 발생할 수 있다.
마스터 노드에 장애 발생 시 슬레이브 노드에 쓰기 연산을 전파하지 않기 때문에 데이터 유실이 없다. 즉, 마스터가 다운되더라도 레플리카는 동일한 최신 데이터를 유지한다.
2.2. 비동기 리플리케이션

반면 비동기 리플리케이션은 마스터 서버에서 변경 사항이 발생한 후, 슬레이브 서버에 적용되는 것을 기다리지 않고 트랜잭션을 완료하는 방식이다. 변경 사항은 나중에 복제본에 전파된다. 빠른 응답시간과 높은 가용성을 제공하지만, 특정 시점에는 데이터 불일치가 발생하는 최종 일관성을 가진다.
마스터 노드에 장애 발생 시 레플리카에 아직 전파되지 않은 트랜잭션은 손실될 수 있다. 때문에 별도의 복구 과정이 필요하다.
- 손실된 트랜잭션을 복구할 것인가?
- 일부 데이터 손실을 감수할 것인가?
3. MySQL의 리플리케이션
MySQL의 리플리케이션은 다음과 같이 Binary Log 기반으로 동작된다.

3.1. 리플리케이션 과정
1. 마스터 서버에서 데이터 변경 발생
INSERT, UPDATE, DELETE 등의 쿼리 실행
2. 바이너리 로그 기록
변경 작업이 바이너리 로그에 기록됨
각 이벤트에는 고유 위치(position)가 할당됨
3. 슬레이브의 I/O 스레드 작동
마스터 서버에 접속하여 새로운 바이너리 로그 이벤트 요청
마스터의 바이너리 로그 이벤트를 슬레이브의 릴레이 로그에 기록
마지막으로 처리한 바이너리 로그 위치를 master.info 파일에 저장
4. 슬레이브의 SQL 스레드 작동
릴레이 로그에서 이벤트를 순차적으로 읽음
이벤트를 슬레이브 데이터베이스에 적용
마지막으로 실행한 릴레이 로그 위치를 relay-log.info 파일에 저장
3.2. binlog 포맷 종류
1. Statement-based Replication
SQL 쿼리문 자체를 복제
장점: 로그 크기가 작음
단점: NOW(), RAND() 같은 함수나 트리거 사용 시 결과 불일치 가능성
설정: binlog_format = STATEMENT
2. Row-based Replication
변경된 테이블 행의 이미지를 복제
장점: 모든 변경사항 정확히 복제 가능
단점: 바이너리 로그 크기가 큼
설정: binlog_format = ROW
3. Mixed Replication
상황에 따라 문장 기반과 행 기반을 자동 선택
장점: 두 방식의 장점 활용
설정: binlog_format = MIXED
3.3. 복제 전략
1. Async Replication
MySQL은 기본적으로 비동기 복제 전략을 사용한다. master는 slave의 복제 성공 여부를 확인 하지 않고 트랜잭션을 완료한다. 앞에서 알아본대로 slave의 복제가 늦어져 조회 시점에 따라 데이터의 차이가 발생할 수 있다.
2. Semi-sync Replication
반동기식 복제 전략은 master에서 slave로 전달된 relay log의 기록이 완료 되었다는 메세지를 받고 나서 트랜잭션을 완료하는 방식이다. 비동기 복제에 비해 성능이 저하되긴 하지만, 데이터의 동기화나 안전성 측면에서 뛰어나다.
3.4. GTID (Global Transaction Identifier)
GTID는 MySQL 5.6 버전부터 도입된 기능으로, 사용 시 데이터베이스에서 발생하는 모든 트랜잭션에 고유한 식별자를 부여하게 된다. 이 식별자는 전역적으로 유일하며, 어떤 서버에서 트랜잭션이 시작되었는지를 명확하게 식별할 수 있다. 마스터 서버에서 트랜잭션이 커밋될 때, 고유한 GTID를 할당하게 되고 트랜잭션 내용과 함께 바이너리 로그에 기록한다.
GTID는 다음과 같이 트랜잭션이 처음 생성된 서버의 UUID인 source_id, 해당 서버에서 발행한 트랜잭션의 순차 번호인 transaction_id로 구성된다.
source_id:transaction_id
이전에 슬레이브가 마스터의 어떤 바이너리 로그 파일과 위치에서 시작할지 수동 지정이 필요했다면, GTID 방식은 슬레이브가 자동으로 아직 수행하지 않은 트랜잭션을 식별하여 복제할 수 있다. 또한 각 트랜잭션이 고유하게 식별되므로 중복 실행을 방지하는 등 MySQL의 복제 시스템 관리를 간편하게 하는 이점을 제공한다.
'CS > 데이터베이스' 카테고리의 다른 글
| Materialized View (3) | 2025.08.03 |
|---|---|
| 리플리케이션 실습 (0) | 2025.06.29 |
| 유일키 생성 전략 (1) | 2025.06.15 |
| 샤딩 실습 (ShardingSphere) (0) | 2025.06.15 |
| 파티셔닝과 샤딩 (0) | 2025.06.15 |