
0. 데이터베이스 분할의 필요성
하나의 데이터베이스 테이블에 데이터가 계속 쌓여서 볼륨이 너무 커지게 되면, 읽기/쓰기 성능은 감소하게 된다. 이때 하나의 테이블이나 데이터베이스 서버를 분할함으로써 이러한 문제를 해결할 수 있다.
1. Partitioning
파티셔닝은 매우 큰 테이블을 여러 개의 테이블로 분할하는 작업이다. 큰 데이터를 여러 테이블로 나눠 저장하기 때문에 쿼리 성능이 개선될 수 있다. 이때, 데이터는 물리적으로 여러 테이블로 분산하여 저장되지만, 사용자는 마치 하나의 테이블에 접근하는 것과 같이 사용할 수 있다.

파티셔닝은 다음과 같이 row 기준으로 데이터를 나누는 수평 파티셔닝과 column 기준으로 데이터를 나누는 수직 파티셔닝이 존재한다.
1.1. 수평 파티셔닝
- 모든 파티션은 동일한 스키마를 가짐
- 각 로우는 오직 하나의 파티션에만 속함
- 쿼리 시에 필요한 파티션에만 접근하여 스캔 범위 축소
- 시계열 데이터 (로그, 거래 내역) 등에 활용
1.2. 수직 파티셔닝
- 각 파티션은 원본 테이블의 일부 컬러만 포함
- 모든 파티션은 공통 식별자(PK)를 유지
- 필요한 컬럼만 포함한 파티션에 접근하여 I/O 감소
- 테이블에 많은 컬럼이 있는 경우 활용
- 대용량 BLOB/TEXT 칼럼이 있는 경우 활용
- 보안상 민감한 컬럼 분리 필요 시 활용
2. Sharding
반면 샤딩은 데이터베이스를 여러 물리 서버(샤드)로 분산시키는 기술이다. 각 샤드는 전체 데이터의 일부분을 정하며, 독립적인 데이터베이스로 작동한다. 쿼리 연산을 병렬로 처리함으로써 확장성과 성능 모두를 향상시키는 방법이다.
샤딩의 경우 다음의 방식들이 존재한다.
2.1. 해시 기반 샤딩

- 샤드 키의 해시 값을 계산하여 특정 샤드에 매핑
- 데이터가 균등하게 분산됨
- 샤드 수 변경 시 재배치 필요
2.2. 범위 기반 샤딩

- 특정 값의 범위에 따라 데이터 분할
- 범위 쿼리에 효율적
- 데이터 불균형 가능
2.3. 복합 샤딩
- 단일 방법만으로 데이터를 효과적으로 분산하기 어려울 때 사용.
- 해시 + 범위 샤딩을 복합적으로 사용.
Line의 DB 샤딩 사례: https://engineering.linecorp.com/ko/blog/line-manga-server-side
LINE Manga 데이터베이스 샤딩 – 서버 엔지니어 편
들어가며안녕하세요. LINE Manga 개발을 담당하고 있는 Ito입니다. LINE Manga의 데이터베이스 샤딩(sharding) 작업에 대해서 서버 엔지니어 편, 데이터베이스 엔지니어 편으로 나누어 소개하려 합니다.
engineering.linecorp.com
2.4. 주의점
성능과 확장성 모두를 챙길 수 있는 샤딩이지만 복잡성이 높고 운영 관리면에서 어려운 점 또한 존재한다.
복잡성 증가
- 어플리케이션 로직이 복잡해짐
- 데이터베이스 관리 및 모니터링 어려움
조인 연산 제한
- 샤드 간 조인이 어려움
- 샤드 간 트랙잭션 처리 복잡
데이터 불균형
- 특정 샤드에 데이터가 집중될 수 있음
리밸런싱 비용
- 샤드 추가/제거 시 데이터 재배치 필요
3. NoSQL의 샤딩
NoSQL은 처음부터 분산 환경을 고려하여 설계된만큼 기본적으로 샤딩 기능이 내장되어 있다.
3.1. MongoDB의 샤딩
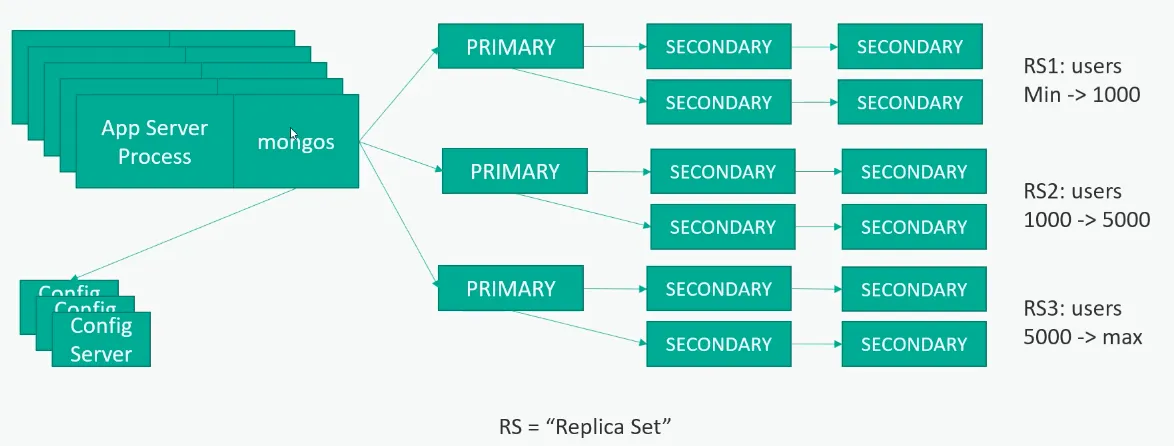
MongoDB의 샤드는 다음과 같이 Replica Set로 구성되어 있다.
- Mongos
클라이언트의 요청을 수신하고, 해당 요청에 적합한 샤드로 라우팅하여 데이터를 처리. 분산 환경에서도 단일 데이터베이스처럼 쉽게 접근 가능 - Config Server
샤드의 위치, 데이터 분포, 샤딩 키와 같은 메타데이터를 관리하며, 클러스터 상태를 유지하는데 중요한 역할을 수행. 일반적으로 3개의 복제본으로 구성되어 가용성을 높임.
각 RS는 주기적으로 OPLog(데이터의 변경사항에 대한 쿼리가 저장되는 별도의 저장영역)에서 로그를 폴링하며 데이터를 동기화한다. 그리고 Secondary DB를 두어 Primary DB에 장애가 발생해도 Secondary DB를 Primary로 승격시켜 복구할 수 있다. 고가용성과 장애 복구 능력 모두 뛰어나지만 많은 복제 set를 관리해야하므로 유지보수 비용이 크다.
3.2. Cassandra의 샤딩

Cassandra는 다음과 같이 각 Node(샤드)를 링 형식으로 구성한다. 각 노드는 해시 링의 특정 범위를 담당하며, 데이터는 파티션의 해시 값에 따라 링에 분산되게 된다.
- 토큰(Token): 파티션 키의 해시값
- 파티션(Partition): 동일한 파티션 키를 가진, 함께 저장되는 레코드 세트
- 토큰 범위(Token Range): 각 노드가 담당하는 해시 공간의 부분
MonogoDB와 비교하여 Primary, Secondary의 구성 없이 모든 노드가 주 서버가 될 수 있다는 특징이 있다.
4. RDB의 샤딩
앞서 살펴보았듯이 NoSQL의 경우 보통 join 연산이 필요하지 않은 단순한 데이터 모델들을 사용하기에 샤딩을 통해 수평적 확장이 가능하다.
반면에 RDB의 경우 중복을 지양하는 정규화된 데이터를 다루는 만큼 테이블간 join이 빈번하여 수평적 확장(샤딩)에 어려움이 있다. 다음 포스팅은 이러한 RDB의 샤딩은 어떻게 구현될 수 있는지 알아보도록 한다.
'CS > 데이터베이스' 카테고리의 다른 글
| Materialized View (3) | 2025.08.03 |
|---|---|
| 리플리케이션 실습 (0) | 2025.06.29 |
| 리플리케이션 (0) | 2025.06.29 |
| 유일키 생성 전략 (1) | 2025.06.15 |
| 샤딩 실습 (ShardingSphere) (0) | 2025.06.15 |