
Redis Cluster에 이어 이번엔 Kafka Cluster를 구축해보도록 하자
1. Kafka Cluster
Kafka Cluster는 여러 개의 브로커로 구성되며 다음의 장점을 가지고 있다.

높은 확장성
수평 확장을 지원하여, 필요에 따라 브로커를 추가함으로써 처리 용량을 쉽게 늘릴 수 있다.
내결함성
각 토픽의 데이터를 여러 브로커에 복제함으로써, 브로커가 실패하더라도 다른 브로커에서 데이터를 유지할 수 있어 시스템의 가용성을 높인다.
2. Replication
Replication은 각 Topic의 Partition을 Kafka Cluster 내의 다른 Broker들로 복제하는 과정을 말한다. 생성된 Replication은 Leader와 Follower로 나뉘며, 이들은 ISR(In Sync Replica)라는 일종의 Replication Group으로 형성되어 관리된다.
다음의 브로커 옵션들을 통해 Replication 관련 설정을 할 수 있다.
2.1. 브로커 옵션
replication.factor
각 Topic의 Partition을 몇 개의 브로커에 복제할지 정하는 설정.
min.insync.replicas
리더 브로커가 메시지를 수신하고 확인하기 위해 필요한 최소한의 ISR(인싱크 복제본) 수.
ISR의 개수가 min.insync.replicas 보다 적게 된다면 Producer에게 예외를 발생 시키게 된다.
2.2. 가용성과 안정성의 균형
공식 문서에 따르면 권장 되는 옵션은 ack=all, replication.factor=3, min.insync.replicas=2이라고 한다.
https://kafka.apache.org/documentation

min.insync.replicas를 replication.factor과 동일하게 설정하면 메시지의 안전성을 가장 높게 보장할 수 있지만, 1대의 브로커에 이상이 생기게 되더라도 전체 시스템에 장애가 생기기 때문에 가용성 면에서 적게 잡는 것이 좋다고 한다.
3. Cluster 구현하기
docker-compose로 간단하게 Kafka 클러스터와 Zookeeper 앙상블을 구현해보자.
docker-compose.yml
version: "3.1"
services:
zookeeper1:
image: confluentinc/cp-zookeeper:latest
container_name: zookeeper1
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_SERVER_ID: 1
ZOOKEEPER_SERVERS: zookeeper1:2888:3888;zookeeper2:2888:3888;zookeeper3:2888:3888
zookeeper2:
image: confluentinc/cp-zookeeper:latest
container_name: zookeeper2
ports:
- "2182:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_SERVER_ID: 2
ZOOKEEPER_SERVERS: zookeeper1:2888:3888;zookeeper2:2888:3888;zookeeper3:2888:3888
zookeeper3:
image: confluentinc/cp-zookeeper:latest
container_name: zookeeper3
ports:
- "2183:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_SERVER_ID: 3
ZOOKEEPER_SERVERS: zookeeper1:2888:3888;zookeeper2:2888:3888;zookeeper3:2888:3888
kafka1:
image: confluentinc/cp-kafka:latest
container_name: kafka1
ports:
- "9092:9092"
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper1:2181,zookeeper2:2181,zookeeper3:2181
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka1:19092,EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092,DOCKER://kafka1:29092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT,DOCKER:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3
KAFKA_MIN_INSYNC_REPLICAS: 2
depends_on:
- zookeeper1
- zookeeper2
- zookeeper3
kafka2:
image: confluentinc/cp-kafka:latest
container_name: kafka2
ports:
- "9093:9093"
- "29093:29093"
environment:
KAFKA_BROKER_ID: 2
KAFKA_ZOOKEEPER_CONNECT: zookeeper1:2181,zookeeper2:2181,zookeeper3:2181
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka2:19093,EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9093,DOCKER://kafka2:29093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT,DOCKER:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3
KAFKA_MIN_INSYNC_REPLICAS: 2
depends_on:
- zookeeper1
- zookeeper2
- zookeeper3
kafka3:
image: confluentinc/cp-kafka:latest
container_name: kafka3
ports:
- "9094:9094"
- "29094:29094"
environment:
KAFKA_BROKER_ID: 3
KAFKA_ZOOKEEPER_CONNECT: zookeeper1:2181,zookeeper2:2181,zookeeper3:2181
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka3:19094,EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9094,DOCKER://kafka3:29094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT,DOCKER:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3
KAFKA_MIN_INSYNC_REPLICAS: 2
depends_on:
- zookeeper1
- zookeeper2
- zookeeper3
kafka-ui:
image: provectuslabs/kafka-ui:latest
container_name: kafka-ui
depends_on:
- kafka1
- kafka2
- kafka3
ports:
- 8080:8080
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka1:29092,kafka2:29093,kafka3:29094
KAFKA_CLUSTERS_0_ZOOKEEPER: zookeeper1:2181,zookeeper2:2181,zookeeper3:2181
networks:
kafka:
driver: bridge
리더 선출 과정
올바르게 클러스터를 구성해주었다면, 리더 브로커에 장애가 생기게 되면 다음의 리더 선출 과정이 자동으로 이루어진다.
1. 리더 장애 감지
Zookeeper가 주기적으로 각 브로커의 상태를 모니터링하여 리더 브로커와의 연결이 끊어지거나 하트비트가 중단되면 장애로 판단한다.
2. ISR 확인
해당 파티션의 ISR 목록을 확인하여 가장 최근에 메시지를 복제받은 팔로워 브로커를 찾는다.
3. 리더 선출
Zookeeper가 컨트롤러 브로커에게 새로운 리더 선출을 지시하고 컨트롤러는 ISR 중 가장 높은 오프셋을 가진 브로커를 새로운 리더로 선정한다.
4. 메타데이터 업데이트
모든 브로커와 클라이언트에게 새로운 리더 정보를 전파하여 메시지 전송/수신을 재개한다.
4. 테스트
마지막으로 리더 브로커의 장애 시에도 메시징 시스템이 원할하게 동작하는지 테스트해보도록 하자.
Topic 설정
먼저, Topic의 레플리카 개수 설정을 3으로 맞춰놓자.
@Configuration
public class KafkaTopicConfig {
@Bean
public NewTopic paymentCompletedTopic() {
return TopicBuilder.name(PaymentTopic.COMPLETED.getTopic())
.partitions(3)
.replicas(3)
.build();
}
}
초기 클러스터 상태
먼저 Producer 어플리케이션 실행 시 다음과 같이 브로커 3이 리더로 선출되어 있는 것을 확인할 수 있다.

메시지 전송 후 브로커 조회 시 다음과 같이 레플리카와 ISR 목록을 조회할 수 있다.
kafka-topics --describe --bootstrap-server kafka3:19094 --topic payment-completed

리더 브로커3 다운
현재 리더 브로커인 3을 다운 시키면 다음과 같이 브로커 1이 새로운 리더로 선출되며, Producer는 에러 없이 작업을 수행할 수 있다.

리더 브로커1 다운
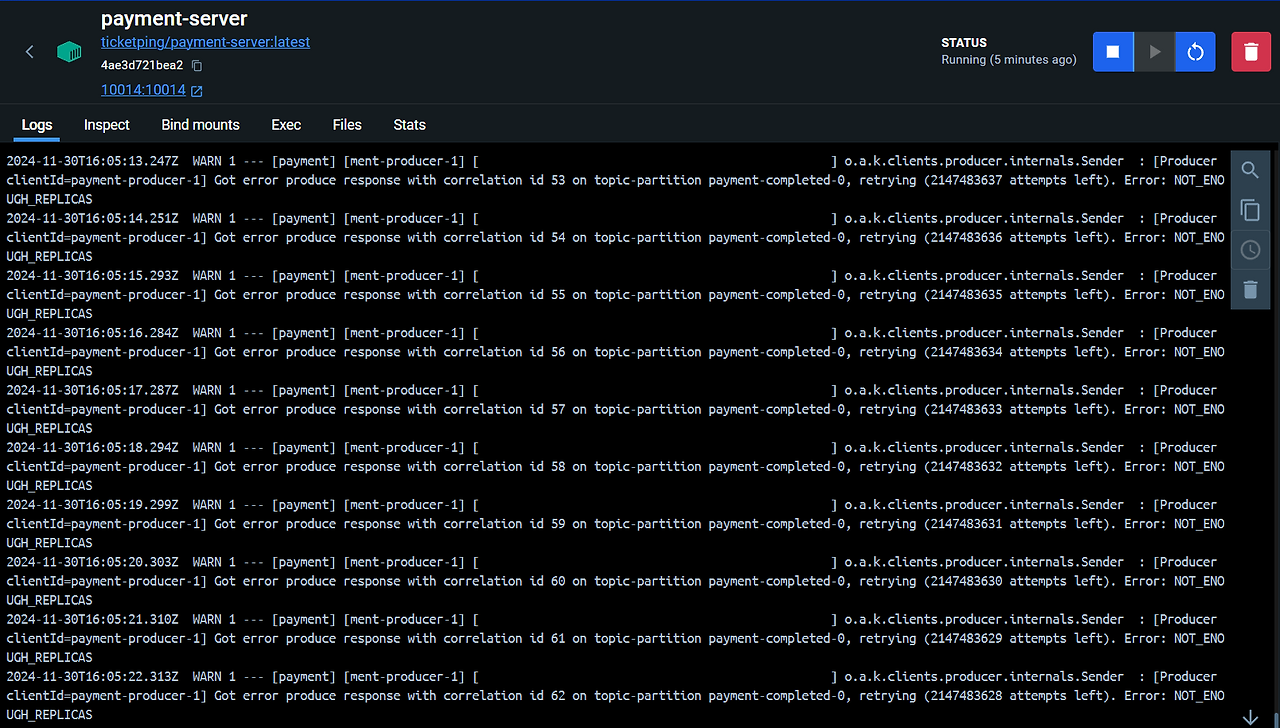
이후 리더 브로커 1마저도 다운시키면, 이때는 ISR 목록에 있는 브로커가 1개 밖에 되지 않아 min.insync.replicas=2 설정에 따라 예외가 발생하는 모습이다.

해당 상태일 때는 메시징 시스템 자체가 멈추므로 브로커를 다시 정상화시켜 ISR에 최소 2개의 인스턴스가 실행되게 해야 한다.
'Project > 티켓핑' 카테고리의 다른 글
| Kafka Consumer 설정하기 (1) | 2025.06.08 |
|---|---|
| Kafka Producer 설정하기 (0) | 2025.06.08 |
| Redis Cluster 구축하기 (0) | 2025.06.03 |
| WebFlux 전환하기 (0) | 2025.05.12 |
| 대기열 진입 동시성 문제 해결하기 (0) | 2025.05.12 |